

Self-Supervised / Unsupervised Learning이 산업 현장에서 주목받는 이유머신비전 검사 시스템은 오랫동안 Rule-based 알고리즘과 Supervised Learning을 중심으로 발전해 왔다.
그러나 최근 2차전지·반도체 공정과 같은 고난도 제조 환경에서는 기존 방식이 구조적인 한계에 직면하고 있다.
이러한 문제의 대안으로 떠오른 기술이 바로 Self-Supervised / Unsupervised Learning 기반 비전 모델이다.
본 글에서는 이 기술이 왜 주목받는지, 그리고 실제 산업 검사에서 어떻게 활용되는지를 중심으로 정리한다.
1. 기존 머신비전 방식의 한계
1) Rule-based 검사
사람이 직접 임계값, 에지, 면적 조건을 정의
신규 불량 유형에 매우 취약
공정 조건 변경 시 반복적인 튜닝 필요
2) Supervised Learning
불량/정상 라벨이 명확할 때는 효과적
현실 공정에서는
불량 샘플이 매우 적고
불량 정의가 계속 변하며
라벨링 비용이 큼
➡ 결국 “불량을 정의해야만 학습 가능한 구조” 자체가 한계가 된다.
2. Self-Supervised / Unsupervised Learning이란?
두 방식의 공통점은 라벨이 필요 없다는 것이다.
차이는 학습 신호를 어떻게 얻느냐에 있다.
구분 | Self-Supervised | Unsupervised |
|---|---|---|
학습 신호 | 데이터 내부에서 생성 | 통계적 구조 |
대표 방식 | Contrastive Learning | Autoencoder |
최근 활용 | 주력 방식 | 보조적 활용 |
최근 산업용 머신비전에서는 Self-Supervised Learning이 중심 기술로 사용된다.
3. Self-Supervised Learning의 개념
Self-Supervised Learning 개념도 (Computer Vision)
라벨이 없는 이미지 데이터를 입력으로 사용하고, 이미지 자체의 변형(회전, 크롭, 밝기 변화 등)을 통해 학습 신호를 생성하는 구조를 나타낸다.
모델은 “같은 이미지에서 나온 변형은 같은 의미를 가진다”는 관계를 학습하며, 이를 통해 의미 있는 시각적 특징을 스스로 형성한다.
머신비전 관점 의미
불량 라벨 없이 공정의 시각적 구조 학습 가능
조명·위치 변화에 강한 특징 표현 확보
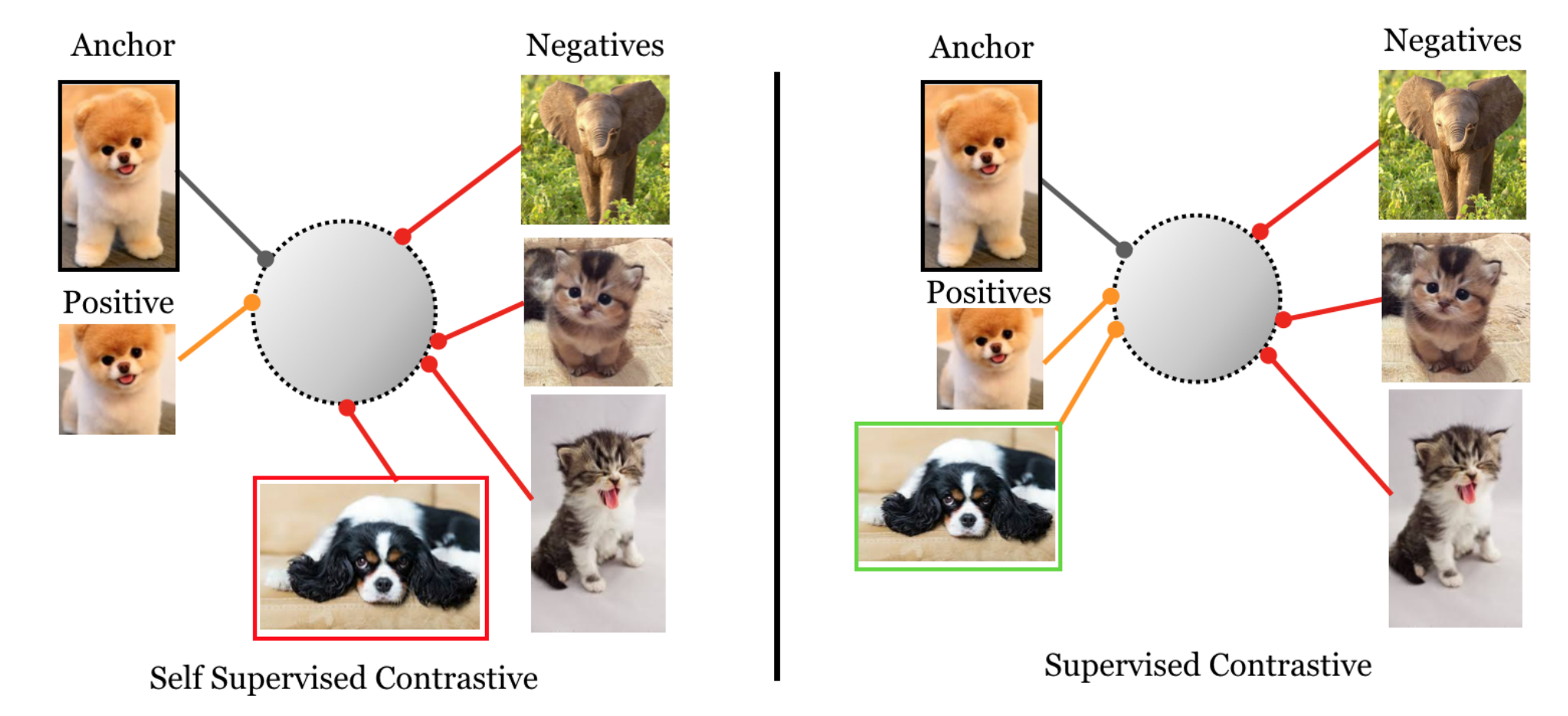
4. 핵심 기술 ① Contrastive Learning
Contrastive Learning의 Positive / Negative Pair 구조
동일한 이미지에서 생성된 서로 다른 변형 이미지를 Positive Pair로, 서로 다른 이미지에서 나온 샘플을 Negative Pair로 정의한다.
모델은 Positive Pair의 특징은 가깝게, Negative Pair는 멀어지도록 학습한다.
산업 검사 관점 의미
정상 제품은 특징 공간에서 밀집
불량은 정상 분포에서 자연스럽게 이탈
신규 불량 유형도 별도 학습 없이 탐지 가능
이는 “불량을 정의하지 않고, 정상의 범위를 학습한다”는 검사 철학의 전환을 의미한다.
5. 핵심 기술 ② Autoencoder 기반 이상 탐지
Autoencoder 기반 이상 탐지 구조
정상 이미지로만 학습된 Autoencoder는 입력 이미지를 저차원 잠재 공간으로 압축한 뒤 복원한다.
정상 이미지의 경우 복원 오차가 작지만, 불량 이미지에서는 복원 오차가 크게 발생한다.
적합한 공정 특성
반복 패턴이 강한 표면
필름, 코팅, 시트류 검사
단, 구조가 복잡한 결함에는 한계가 있어 최근에는 Contrastive 기반 특징 추출과 병행하는 경우가 많다.

6. 산업용 이상 탐지 적용 예
산업용 머신비전 이상 탐지 결과 예시
정상 데이터만으로 학습된 모델이 실제 검사 이미지에서 이상 영역을 히트맵 또는 마스크 형태로 강조 표시한다.
현장 적용 의미
불량 정의가 어려운 공정에서도 즉시 적용 가능
초기 양산 단계에서도 검사 시스템 구축 가능
검사 기준 변경 시 재라벨링 부담 최소화
7. 공정별 적용 사례
1) 2차전지 공정
미세 핀홀, 얼룩, 코팅 불균일 등 불량 정의가 유동적
Self-Supervised 기반 접근 시:
정상 패턴 분포 학습
고객/공정 기준 변경에도 유연 대응
2) 반도체 공정
불량 유형 수십~수백 종
초기 양산 시 불량 데이터 부족
정상 기반 학습으로 조기 검사 가능
8. 기존 방식과의 비교
항목 | Rule-based | Supervised | Self-Supervised |
|---|---|---|---|
라벨 필요 | 없음 | 많음 | 없음 |
신규 불량 대응 | 매우 낮음 | 재학습 필요 | 매우 높음 |
공정 변경 대응 | 취약 | 보통 | 강함 |
장기 유지보수 | 어려움 | 어려움 | 상대적으로 쉬움 |
9. 도입 시 유의사항
정상 데이터 품질이 성능을 좌우
초기에는 정상 정의를 넓게 설정
고정 임계값보다 분포 기반 기준 권장
완전 자동보다는 Human-in-the-loop 구조가 현실적
마무리
Self-Supervised / Unsupervised Learning은
“불량을 정의해서 찾는 검사”에서
“정상을 학습해 벗어남을 찾는 검사”로의 전환이다.
라벨 비용, 신규 불량 대응, 공정 변화라는 현실적인 문제를 고려할 때
이 접근은 더 이상 연구 주제가 아니라 산업 현장에서 검증되고 있는 기술이다.